How Hivebrite Makes Quality Visible at Scale (Part 1)

January 6, 2026
This post is for engineers curious how we scale quality in a fast-moving SaaS product. It covers the operating system behind our approach: shared ownership, early alignment rituals, structured QA planning, risk-based prioritisation, and automation gates we trust.
Introduction
As SaaS products scale, quality problems rarely come from one “big” failure. They come from accumulated risk: more teams shipping in parallel, more configuration paths, more customer contexts, and more edge cases.
Hivebrite hit that stage. “QA at the end” stopped working — not because QA wasn’t good enough, but because the system wasn’t designed for scale. The only sustainable option is to make quality shared, measurable, and visible across Product, Engineering, QA, and Support.
That’s what we built: a way to align early on what matters, prioritise risk consistently, and scale automation without losing trust in it.
Our view on quality
At Hivebrite, QA is not just a gate — it’s a partner in delivery.
Quality isn’t something added at the end of a cycle. It’s a continuous, collaborative effort that starts during discovery and continues through delivery and beyond.
Our role in QA is to help teams:
- Understand risk early
- Clarify expectations
- Build confidence that what we ship behaves as intended for users
This mindset is formalised in our QA Manifesto.
Our QA Manifesto
Our manifesto isn’t a checklist. It’s a set of principles that guide day-to-day decisions across squads:
- Quality is shared — QA enables quality; squads own it together.
- Testing starts with understanding — a story isn’t ready until risks and scope are clear.
- We plan before we test — preparation drives speed.
- Prevention beats detection — better questions early mean fewer late surprises.
- Automation serves insight — confidence over vanity metrics.
- Clarity over volume — evidence should support decisions.
- Consistency without rigidity — standardise where it helps, adapt where it matters.
- Continuous learning — every release is a feedback loop.
Shared rituals: refinement and Three Amigos
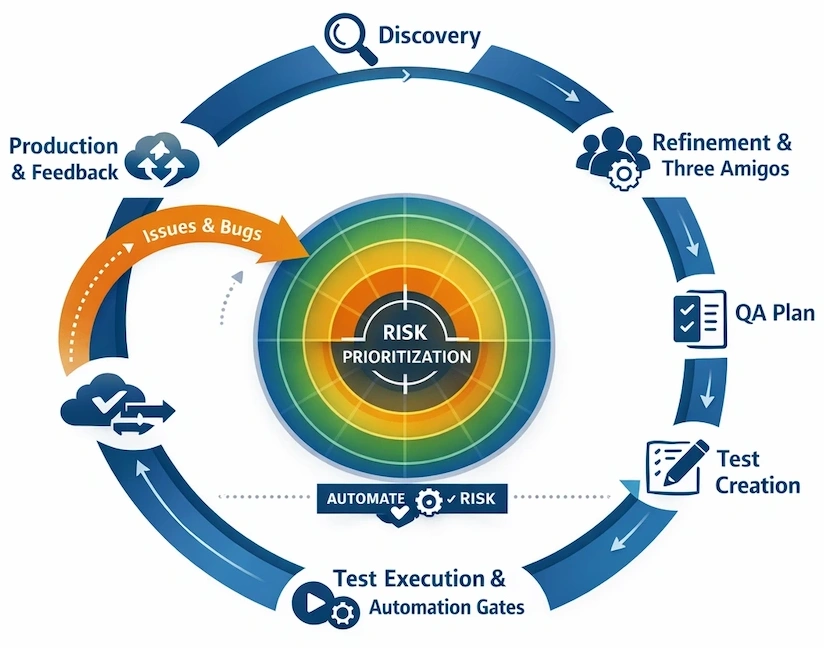
Early alignment is critical. At Hivebrite, we rely on two complementary rituals before development begins: backlog refinement and Three Amigos.
Refinement: building shared understanding over time
Refinement is part of continuous planning. It lets teams clarify requirements as understanding evolves.
Refinement helps us:
- Improve requirements as new information emerges
- Break work into estimable, executable user stories ready for implementation
- Reduce ambiguity with well-defined acceptance criteria
- Build shared understanding across the squad
Three Amigos: focused alignment for complex or risky work
While refinement supports continuous clarity, Three Amigos meetings are used more selectively.
A Three Amigos brings together:
- The PO/PM
- The QA Analyst in the squad
- The Tech Lead (or a developer)
Its purpose is to deep-dive on user stories with higher complexity or risk, especially when:
- Non-functional requirements are critical (performance, accessibility, security)
- Technical implementation is complex or has broader impact
- User flows or migrations need careful review
- Rollback or data integrity scenarios must be anticipated
By combining product, technical, and quality perspectives early, teams can surface issues before implementation begins — from edge cases and flow inconsistencies to performance, security, or accessibility concerns.
How the two work together
Refinement and Three Amigos are not exclusive — they reinforce each other.
Refinement often surfaces changes or uncertainties that signal the need for a focused Three Amigos discussion. In those cases, a smaller group can quickly align on implications, validate assumptions, and shape a clear QA and technical approach.
Not every story requires a Three Amigos. We reserve it for work where early collaboration delivers the most value.
This balance allows teams to move fast on straightforward changes while investing deeper thinking where risk and complexity demand it.
From shared understanding to a clear QA plan
Each feature is supported by a lightweight but structured QA plan.
The plan answers a few essential questions:
- What is in scope for this release?
- Which functional areas are most critical?
- Where are the main risks?
- What testing is required?
- What is intentionally deferred?
Reviewed with Product and Engineering before execution, this plan makes expectations explicit and keeps QA a decision enabler, not a late-stage blocker.
For significant changes, QA Analysts share a short overview with the broader team to surface integration risks and reduce regressions.
Risk-based bug prioritisation
As our product and customer base scaled, prioritising bugs based on urgency or gut feel created inconsistency and friction. We address this with a simple, transparent risk-based system we call the Bug Prioritisation Abacus (an internal Chrome extension).
Each reported issue is evaluated across three dimensions, from 1 (lowest) to 4 (highest):
- Functional criticality — how central the affected area is to the product and customer workflows
- User impact — the severity of the effect on users when the issue occurs
- Occurrence — how frequently the issue is observed in real usage
By combining these perspectives, teams assess bugs based on risk and customer impact, rather than individual perception or short-term pressure.
This notion of functional criticality extends beyond triage. We also use it in test management to tag test cases, so teams can quickly see what protects core journeys vs. lower-risk areas.
In practice, this approach:
- Creates a shared language across Product, Engineering, QA, and Support
- Reduces subjective debates during triage
- Aligns test coverage with real product risk
- Keeps attention focused on the problems that matter most to users
It enables more predictable planning and faster decision-making, while maintaining consistent quality across squads.
Making automation visible and trustworthy
Automation is a key part of how we scale quality, and we treat it as a confidence mechanism.
As of early 2026, our test suite includes 3,644 active tests:
- 1,844 manual tests (≈51%)
- 1,558 automated tests (≈43%)
- 242 tests (≈7%) identified as automation candidates
This balance is intentional. Manual testing remains essential for exploration and early-stage features, while automation focuses on stable, high-value user paths.
Quality gates over raw coverage
Not all automated tests are equal.
We rely on quality gates to signal trust at different stages of the deployment pipeline:
Deployment gates run before code reaches pre-release environments. A selected suite of Playwright and Cucumber end-to-end tests acts as an early filter — if tests fail, the deployment is blocked until the issue is resolved. This catches critical instability before it reaches later stages, saving time and providing fast feedback. The QA Automation Engineer on Duty monitors these gates and works with developers to resolve blockers quickly.
Release gates are the final checkpoint before production. After code is deployed to an ISO-production environment with all feature flags activated, critical Playwright tests covering essential user journeys run one last time. Only if all tests pass does the QA Automation Engineer give the go-ahead for production deployment. Any failure blocks the release until addressed.
New tests must first prove stability before being promoted to either gate. This prevents false confidence and keeps automation accelerating delivery rather than slowing it down.
Together, these gates ensure that only builds meeting strict quality standards reach customers, while catching issues as early as possible in the pipeline.
Stability as a first-class metric
Automation health is treated as a quality signal — both before and after deployment.
Pre-release: Across our automated suite, instability is kept low. Flaky automated Playwright tests or muted tests are addressed quickly to preserve trust. When automation fails, teams can act with confidence rather than doubt.
In production: Automated tests run every 20 minutes across all main production regions (US, EU, APAC, CH) on dedicated test networks. These tests monitor core features like login, group navigation, and user settings. If any fail, the production support team is immediately alerted to investigate and resolve the issue. This continuous monitoring catches problems that may emerge after deployment and provides real-time visibility into production health.
Automation as a roadmap
Automation decisions at Hivebrite are guided by risk, maintenance cost and added value, not volume.
Rather than automating everything by default, manual tests are continuously evaluated using a structured decision matrix to determine which scenarios are:
- High-value automation candidates, where automation brings clear and lasting benefits
- Better left manual, typically due to volatility or low long-term return
- Deferred, pending greater product or functional stabilisation
Each scenario is reviewed against a consistent set of criteria designed to maximise impact and sustainability:
- Frequency of execution — scenarios executed often benefit most from automation
- Repetitiveness — time-consuming, repetitive tests are strong candidates
- Business criticality — core user journeys and high-risk flows are prioritised
- Feature stability — automation is favoured once behaviour is stable
- Data setup complexity — scenarios with simple, reusable data are easier to maintain
- Return on investment — long-term maintenance cost versus execution savings
- Technical feasibility — suitability for existing automation frameworks
By evaluating tests through this lens, automation becomes a deliberate, evolving roadmap rather than a growing backlog. Effort stays focused where it protects critical journeys and remains sustainable.
Why this matters for customers
All of these practices — early QA involvement, risk-based prioritisation, structured planning, and intentional automation — exist for one reason: customer trust.
In practice, this approach means:
- Fewer regressions in production, because critical user journeys are explicitly identified, prioritised, and protected by targeted testing and reliable automation
- More predictable releases, thanks to clear quality gates, explicit risk assessment, and shared understanding of what “done” means
- Faster iteration without repeating mistakes, as incidents and bugs are systematically turned into durable test coverage rather than one-off fixes
- Stronger confidence in critical paths, supported by objective prioritisation, stable automation, and continuous validation of what matters most to users
By making quality visible and intentional at every stage, we reduce surprises and help teams move fast with confidence.
What’s next
As development teams increasingly adopt AI-assisted workflows, QA must evolve alongside them to avoid becoming a bottleneck in the software development life cycle.
At Hivebrite, we’re integrating AI tools into QA to accelerate analysis, documentation, test generation, and decision-making — not to replace human judgment, but to enhance it. We’re using the same tools developers use daily: Cursor (custom rules and prompts), Claude Code, and Dust.
In a follow-up post, we’ll share how we use internal AI assistants and developer-facing AI tools to:
- Close the gap between QA and development speed
- Turn bugs, incidents, and product knowledge into actionable test assets
- Keep quality scalable without sacrificing rigor
Stay tuned.
Closing thoughts
Quality is not a phase, a checklist, or a role. It’s a shared discipline that evolves with the product and the organisation.
At Hivebrite, our goal is simple: move fast without breaking things twice.